Optimizing FSL and SPM
Optimizing FSL and SPM¶
Magnetic Resonance Imaging (MRI) provides powerful tools for understanding how the healthy brain functions, and can also provide insight into developmental and neurological disorders. However, to make these inferences we need to heavily process the images, dealing with common sources of noise and adjusting for individual differences in the brain shape and architecture. These steps are computationally intensive, and can take a while even with the fastest modern computers. This page provides suggestions for selecting the best hardware for analyzing brain imaging data.
My center is currently conducting a large study to understand the consequences of stroke. We hope to provide accurate prognosis and tailor the optimal treatment strategy for future neurological patients. This study acquires and analyzes a broad range of modalities:
Lesion maps are drawn on T2-weighted scans which are aligned to T1-images. We then perform Enantiomorphic normalization . This allows us to understand the influence of the size and location of the brain injury. The normalization parameters are used for the subsequent stages. This stage uses SPM.
We analyze :ref:` Arterial Spin Labelling <my_asl>` using the SPM-based ASLtbx . This allows us to investigate perfusion.
We analyzing resting state data using our own SPM-based toolbox.
We process our diffusion tensor imaging (DTI) data using a series of FSL tools including topup, eddy, dtifit, bedpostx, and probtrackx.
We quantify the DTI results using our own SPM-based routines, allowing us to understand how the brains’ connectivity correlates with the cognitive and behavioral limitations observed following stroke.
The table below shows the time required to analyze these stages for a single individual using two computers that each cost about $700. The i7-4790K is a modern (in 2015) quad core CPU with hypterthreading (e.g. appearing to have 8 CPUs), while the dual X5670 computer has 12 cores (24 hyper threads) and was released in 2010 and purchased used from eBay (with only a modern solid state disk added):
Hardware |
T1-SPM |
ASL-SPM |
Rest-SPM |
DTI-FSL |
DTI-SPM |
Total |
|---|---|---|---|---|---|---|
4.00 Ghz 4790k 4 core |
238 |
77 |
106 |
4154 |
234 |
4810 |
2.96 Ghz X5670 12 core |
449 |
143 |
207 |
2838 |
307 |
3944 |
Speed-up |
1.88 |
1.86 |
1.95 |
0.68 |
1.31 |
0.82 |
SPM considerations¶
For my pipeline, SPM only requires a minority of the processing time. So for my DTI-studies I really need to focus on optimizing FSL rather than SPM.The architects of SPM deserve a lot of credit for optimizing this tool out of the box. It is heavily vectorized and takes advantage of Matlab’s implicit multithreading. Therefore, some stages see some benefit for having a lot of cores. Likewise, for specific situations where Matlab is not efficient the designers have crafted mex files that speed analysis. The performance benefit of the modern 4790K (Haswell) CPU over the older X5670 (Westmere) is more than one would expect due to clock speed alone. This certainly reflects design improvements in the new chips, but may also reflect that recent versions of Matlab use advanced features such as AVX2.In general, SPM seems well suited to inexpensive, consumer computers.
FSL considerations¶
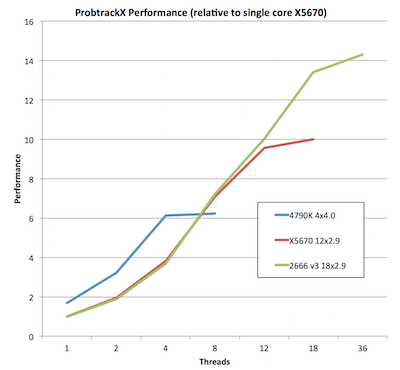
Many of the slow FSL tools can be run in parallel. Therefore, the number of cores available can dramatically accelerate performance (see graph).
Hyperthreading does not help FSL performance. Performance is limited by the number of physical cores. Note that the 4790K has 4 physical cores but 8 logical cores (e.g. hyper threads). However, performance for this processor does not improve when more than 4 cores are used (see graph).
Beyond clock-speed, modern CPUs show little or no improvement over 5 year old CPUs for FSL’s probtrackx and bedpostx tools (which are the bottlenecks in my pipeline). This is unlike other programs, where the newer processors are much faster. For example, SPM shows a 68% improvement for the modern 4.4GHz 4790K versus the 2.93 GHz X5670 (released March 2010), while with FSL the improvement is just 35% improvement. This can be best seen by comparing the older 2.9 Ghz X5670 Xeon (dual, for 12 cores) to the 2.9 Ghz Xeon E5 2666 v3 (released in April 2016, with 18 cores). Note that when we limit ourselves to 12 cores these systems provide identical performance.
The pre-compiled FSL distribution is pretty generic (supporting all 64-bit x86 CPUs with the “-m64” option), and is not tuned to modern CPUs. One strategy might be to recompile FSL on your latest generation CPU using the “march=native” directive.
FSL’s native distribution is designed to work on old computers, and omits useful instructions added to recent CPUs (such as AVX ). Therefore, the easiest way to test this is to either build FSL using a more recent Fedora distribution or use the CERN devtoolset that ports recent versions of GCC to CentOS 6.x.
In my brief exploration of this I found no benefits for using these advanced features for the FSL tools that are slow for me (bedpostx and probtrackx): Haswell computers took just as long to process data using the default compiler settings (which can work on any 64-bit x86 computer) as when the tools were recompiled to take advantage of the latest Haswell features (using gcc 4.8.2 on CentOS and 4.9.2 with Fedora, both using “march=native”). Perhaps these routines are not ideal for these new functions, or perhaps the compiler needs some hints . In my (limited) experience, AVX does not provide huge benefits over SSE for most algorithms (unlike SSE vs x86 ). See also the CERN ’s experience with AVX.
Note that bedpostx can run faster if you can use a high-end graphics card (GPU) instead of the central processing unit (CPU). In testing with Ben Torkian we found a GTX Titan about 85 times faster than a single core of a 4770k. Of course, in reality we would provide multiple CPUs to this task, and there even the GPU requires some CPU-based house keeping. Therefore, a more realistic comparison using our datasets finds bedpostx requires about 1362sec using all four cores of a 4790k, while a NVidia TitanZ on an older computer requires about 135sec. Beyond FSL, GPUs can accelerate many neuroimaging tasks, and can be easily integrated into Matlab as explored in my work with the Research Cyberinfrastructure group . Generally, for accuracy many scientific computations use double-precision calculations which are much faster on the workstation-class GPUs (NVidia’s Tesla systems, and some models of the Nvidia Titan). However, bedpostx_gpu seems to run pretty quickly on commodity GPUs (that typically have fast single precision but slow double precision). For example, I found a Nvidia GTX 970 is able to process our DTI dataset in just 169 seconds. GPUs can accelerate other slow tasks – for example Moises Hernandez from the FSL group allowed me to beta-test his probtrackx2_gpu and an old computer with a Titan Z was able to compute a dataset in just 451 seconds where a 4 core 4790K CPU required 2465 seconds and a 18 core Xeon v3 required 1125 seconds.
Optimizing FSL, cost no object¶
If cost is no object, you will want a large computer cluster for FSL , with GPU nodes if you use bedpost.
Optimizing FSL, on the cheap¶
- At least for my DTI analyses, it is clear that FSL really thrives when provided with lots of cores, but does not care much if they are the latest generation. Further, since many of the parallel tasks are conducted in 2D, you do not typically need a lot of RAM. Given this, you can take advantage of the fact that many companies purchase their servers on 5 year leases. Therefore, you can visit eBay and purchase a 5-year old cluster for pennies on the dollar. You can see that my 5-year old 12-core X5670 that I purchased used and upgraded with a SSD (total investment of $700) delivers about 70% of the performance of the latest 18-core Xeon e5 v3 (where the CPU alone cost more than $4000). Combining a few old computers together with Sun Grid Engine could provide a very inexpensive cluster.
Darek Mihocka made an excellent suggestion that one could use the cloud to process data. Indeed, for this evaluation I rented a high-end Xeon e5 2666 v3 system for evaluation (referred to as a c4.8xlarge by Amazon web services). This is a great way to evaluate whether the latest hardware provides you with a performance boost relative to your current equipment. Further, if you only need to occassionally process datasets it is probably much less expensive to rend a cloud server than invest in your own server.
Optimizing FSL, without a cluster¶
Typically, to parallelize FSL you need to install grid engine software such as Condor or Son Of Grid Engine . However, this is inconvenient if you have a simple Linux workstation or a Linux laptop. In addition, grid engines are now effectively not installable on Apple Macintosh computers running MacOS (macOS). One can take advantage of the fact that any FSL program that is able to use a grid engine will submit a job FSL’s ‘fsl_sub’ script. By default, this if a grid is not available the job will be computed by a single core. With a little modification we can change this behavior so that if a grid is not available you will use all the available cores. To do this:
Download this modified version of fsl_sub
Install this new version. Here I assume the downloaded file is in your Downloads folder with the name ‘fsl_sub.txt’ and fsl is installed in /usr/local/fsl:
sudo cp /usr/local/fsl/bin/fsl_sub /usr/local/fsl/bin/fsl_sub_orig
sudo cp ~/Downloads/fsl_sub.txt /usr/local/fsl/bin/fsl_sub
sudo chmod +x /usr/local/fsl/bin/fsl_sub
At this stage, you can run FSL as usual, and hopefully it will be faster.
If you want to test the benefit, you can temporarily disable the function by using the command “FSLPARALLEL=0; export FSLPARALLEL”
If you want to test the benefit, you can temporarily force it to use precisely 8 cores with the command “FSLPARALLEL=8; export FSLPARALLEL”
If you want to test the benefit, you can temporarily force it to automatically detect the number of cores (the default behavior) with the command “FSLPARALLEL=1; export FSLPARALLEL”
To make permanent changes, add the desired FSLPARALLEL setting to your profile, for example if you are using the bash shell you could type ‘nano ~/.bash_profile’ to configure your shell .
Optimizing zlib¶
Unlike SPM, FSL (and many other neuroimaging tools) will save brain images in the compressed .nii.gz format. This saves disk space required by the files. FSL (like most tools) dynamically link to the zlib library to compress and decompress these images. While decompression is fast (indeed, for the slow disks often found on clusters it may be faster to read compressed images than raw images), the compression is very slow. A simple trick to accelerate all of these tools is to replace your zlib with the Cloudflare zlib . This is a drop-in replacement for zlib that utilitizes the SSE 4.2 instructions (Linux/MacOS, CPUs since 2008) or AVX instructions (Windows, CPUs since 2011) of modern computers. This zlib library remains single threaded (unlike pigz), so influence any other processes running on your cluster. Your compression instantly becomes faster. You do not need to recompile FSL or any other tools: any tool that dynamically links to zlib will experience faster compression. Below you can see the impact of this. Here we use a fast local disk to read an uncompressed 16-bit integer image and save it as a compressed 32-bit image (the default output of fslmaths). This example emphasizes the impact of accelerated compression (x3.25 times faster). However, each fsl stage of (and any other tool that uses zlib) will benefit. As an added benefit, notice in this example that the Cloudflare zlib (1.2.8) compresses the file to a smaller size than the original zlib (1.2.3).
AFNI users can set install a Cloudflare accelerated pigz and set the AFNI_COMPRESSOR=PIGZ environment variable for improved performance.
Future Considerations¶
Like other centers, we upgraded our Siemens Trio to the latest generation Prisma. The Human Connectome Project sequences show the dramatic benefits due to many features including new gradients, reduced dielectric effects and advanced multi-band tricks. However, this will mean substantially more data to process. While most modalities will an increase of x2-x3, the DTI sequences will see a dramatic increase in both resolution and directions. This means that GPU and cluster based solutions will become increasingly necessary for DTI analyses.
This page focuses on Intel/AMD architectures. However, recent ARM-based CPUs show considerable promise. For example, the Apple M1 CPUs released in 2020 .